
av Mikael Winterkvist | dec 16, 2024 | Bluesky, Mastodon, Nätfrihet, Threads
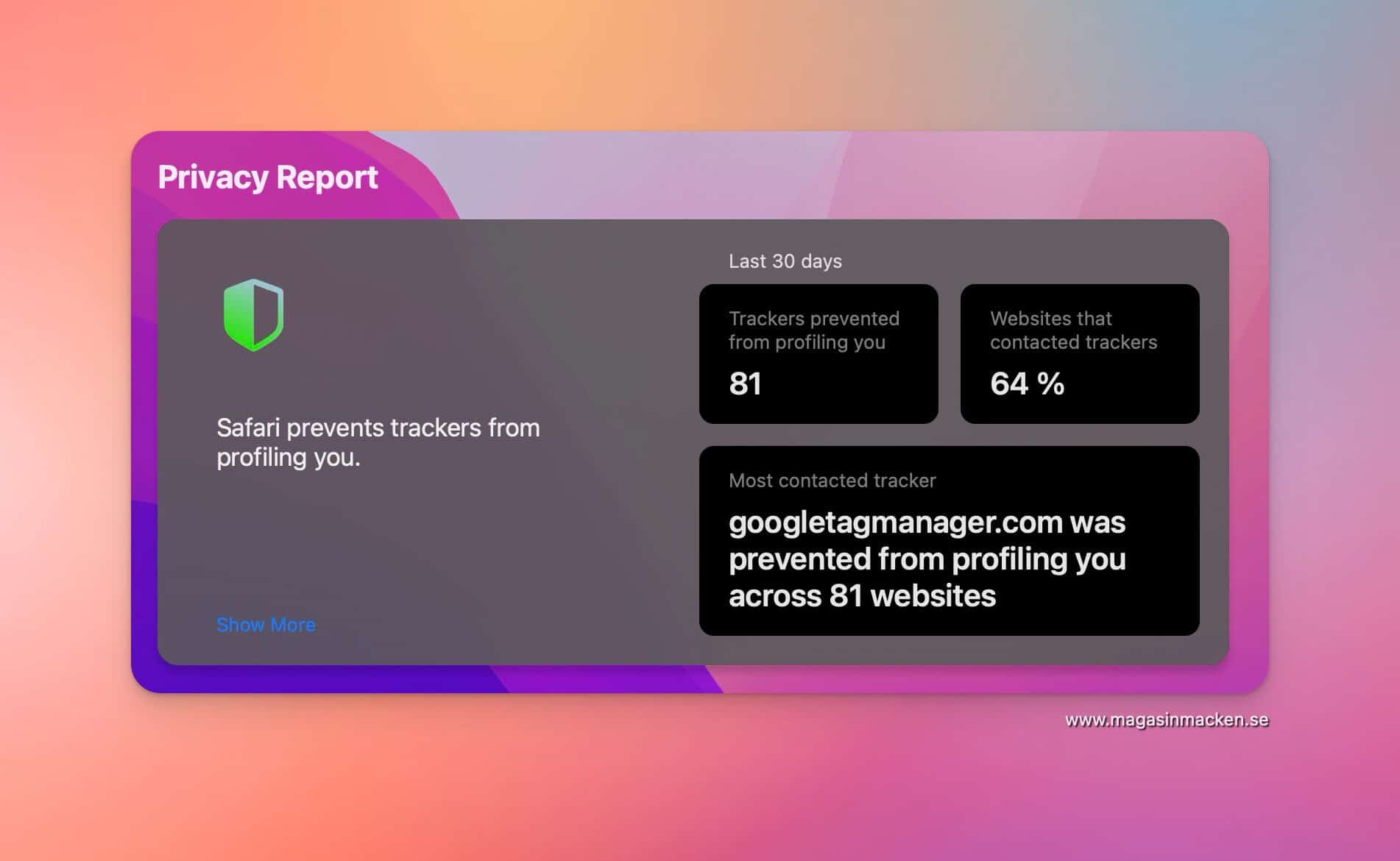
Google Tag Manager – Googles verktyg för att samla in data om vad vi gör ute på nätet försöker kartlägga det jag gör – nästan tre gånger dag, varje dag.
Kom då ihåg att jag inte använder Googles tjänster – inte sökmotorn, inte Googles Documents. hade jag använt någon av Googles tjänster och hade jag använt Android så hade siffran stigit – markant.
Så här ser det ut – ute på nätet, året om, varje dag – så snart du använder Internet och surfar runt bland olika webbplatser.
Så här ser kartläggningen av dig ut – ute på nätet
Det är en av flera anledningar till att jag valt Apples plattform och varför jag använder Safari och Brave som webbläsare.

av Mikael Winterkvist | dec 1, 2024 | Bluesky, Mastodon, Nätfrihet, Threads
Datatrålarna, datamäklarna – de som samlar in enorma mängder data om oss och som sedan förpackar den för försäljning till allehanda kunder utgör ett växande säkerhetsproblem. Medan vi ställer krav på Facebook, Google och andra att de ska förvara våra data på ett söker sätt så går de här informationssäljarna under radarn.
Ett exempel:
En säkerhetsforskare hittar en stor databas med bakgrundskontroller tillhörande över 600 000 individer. Det är PDF-filer som innehåller information om domar, ekonomi, fastighetsinnehav, komplett bostadsadress, epost, Social Security Number (amerikansk motsvarighet till personnummer) och en rad känslig, personlig information.
Databasen ligger uppe på nätet – helt skyddad – okrypterad utan vare sig krav på inloggning eller lösenord. Information hittas av en säkerhetsforskare som slår larm. Företaget, svarar inte på de första varningarna och det går flera veckor innan databasen plockas ned och plockas bort.
Stor läcka – datamäklare lämnade databas helt oskyddad i veckor
Personuppgifter
Det är tyvärr inte det enda exemplet – i augusti i år så började personuppgifter om miljontals amerikanska och kanadensiska medborgare att florera på nätet. En gigantisk databas bjöds ut till försäljning via digitala mötesplatser på The Dark Web.
Uppgifterna kom från National Public Data, ett företag som samlar in och säljer tillgång till personuppgifter för användning vid bakgrundskontroller, för att få ut kriminalregister för arbetsgivare, exempelvis. National Public Data, NPD, tros skrapat denna information från offentliga källor för att sammanställa individuella användarprofiler för personer i USA och andra länder.
Lägg sedan till att på en enda webbplats så kan de data som samlas in om dig delas med, håll i dig nu, över 1 500 enskilda mottagare – datatrålare, datamäklare som levde på att samla in vår in formation och sedan sälja den. Det är affärsidén.
Din information kan delas med över 1 500 bolag när du surfar runt ute på nätet
Spöken
Det här handlar inte om att vara överdrivet paranoid, misstänksam eller om att se spöken mitt på ljusan dag. Det handlar om att enorma mängder insamlad data om oss lagras, skickas och hanteras på ett i grunden helt förkastligt sätt ur säkerhetssynpunkt.
Svårigheten är att även om vi skapar regler och lagar så är de svåra att tillämpa. Till att börja med måste vi veta att de här bollen överhuvudtaget existerar och att de samlar in vår information – vilket inte är det lättaste. Sedan måste vi avgöra var de här datatrålarna är verksamma, i vilket land för att kunna avgöra vilken lagstiftning som vi ska tillämpas.
Enbart juridiken runt affärsverksamheten gör att det är lätt att tappa bort sig och inte riktigt veta hur problemet ska lösas. Du som enskild användare vet förmodligen inte ens vart du ska vända dig eller vilka rättigheter som du har.
Har ett amerikanskt bolag samlat in data om dig och blivit av med informationen för att den lagrats oskyddad ute på nätet så råder det ingen tvekan om vem som gjort fel men ansvaret är allt annat än enkelt att utkräva.
Sedan tillkommer då även problemet med hur all denna data lagras och det finns alltför många skrämmande exempel att de som samlar in och som köper och säljer vår information inte går att lita på.
av Mikael Winterkvist | nov 24, 2024 | Bluesky, Mastodon, Nätfrihet, Threads
Den personliga integriteten, min information, min personliga information är hårdvaluta ute på nätet och det finns en rad multinationellt, stora teknikjättar vars affärsidé är att samla in data, bearbeta den och sälja informationen vidare. Här är Mackens Guide för att komma undan datatrålarna.
Plötsligt studsar du till, i ditt flöde av information ute på nätet dyker det plötsligt annonser om något dom du har funderat över att köpa men som du så vitt du vet inte har sökt efter på nätet eller skrivit om. En misstanke föds och du tittar på din iPhone – ”Är jag avlyssnad?” eller ”Läcker mina elektronisk prylar information?”.
Känns det igen – har det hänt dig?
Svaret på frågorna är nej och ja. Du är inte avlyssnad men dina elektroniska kan mycket väl läcka information som Facebook eller Google lyckats att pussla ihop för att ta reda på vad du planerar att köpa. Det är ett bevis på att kartläggningen av dig som individ faktiskt fungerar.
Byt till plattform
I den här genomgången så är flera av råden att byta till Apples plattform och även om jag vet att det inte är realistiskt och att alla inte gillar Apple så handlar det om att byta till en tjänsteleverantör som inte har som affärsidé att samla in data om dig och plocka åt sig av din personliga information. Ska du ha tillgång till en rad tjänster, kunna använda nätet, surfa runt samtidigt som du lagrar data på andra platser än hemma lokalt så kan du inte ha kakan och äta den. Det handlar också om tillgänglighet och användarvänlighet. Ska du göra saker så fungerar det inte med att du varje gång måste sitta och traggla dig igenom ändlösa radera med inställningar för att försöka att minska mängden data som skickas ifrån dig. Därför är rådet att se över dina tjänsteleverantörer, dina behov och om du störs av att andra samlar in data om dig – byta plattform.
Förklaringen
Till att börja med ska sägas att vare sig Google, Facebook eller någon annan av teknikjättarna behöver veta vem du är som individ för att kunna samla in information om dig. De behöver inte veta, och de struntar faktiskt i vem du är, vad du heter men däremot håller de reda på var du bor, var dina prylar finns, vilka du umgås med ute på nätet Puch de följer mycket noga vad du gör ute på nätet därför att det är grunden i deras datatrålande.
Genom att samla in information om vilka webbplatser som du besöker, vilka annonser du klickar på, vad du söker efter och vad du gör så kan du som individ kartläggas och släng in ålder, geografi i ekvationen så kan du placeras i en grupp som statistiskt motsvarar den du är – din digitala personlighet. Sedan kan datatrålarna bara fylla på med mer data, mer information för att komplettera bilden av dig och det utan att du ens behöver att använda just deras tjänster eller besöka deras webbplatser.
Samarbete
Vi bortser ifrån, och missar ofta, att Facebook, Google, Amazon och andra samarbetar med en lång rad andra webbplatser och att har tjänster och funktioner som läggs in på andra webbplatser. Med hjälp av digitala fingeravtryck vet de att det är du som loggar in på en webbplats, besöker en webbplats eller använder en tjänst. Du kan som bekant logga in med Google, logga in Facebook, lagra dina bilder hos Google, ha din e-post hos sökjätten och förutom allt det så äger jättarna andra webbplatser – Instagram, WhatsApp och Youtube för att ta några exempel.
Insamlingspunkterna, möjligheterna för datatrålarna att hitta information och samla in den är om inte oändliga så näst intill.
Så hur minskar du då exponeringen mot Google, Amazon, Facebook och de andra datatrålarna?
Genom att ge upp en del av din bekvämlighet, välja andra produkter och tjänster och genom att säga nej men tro inte att du kan hålla dig undan helt och hållet och tro inte att du kan lyckas med att se till att datatrålarna helt tappar bort dig och att du kan surfa runt ute på nätet helt anonymt. Det går men det är inte enkelt och det kräver rätt radikala åtgärder som inte passar de flesta av oss. Du kan däremot minska mängden va data som de kan smala in om dig – du kan göra det svårare att kartlägga dig.
Byt sökmotor
Börja med att byta sökmotor – kasta ut Google och byt till DuckDuckGo eller någon annan sökmotor som garanterat att det du söker och det du gör inte kartläggs.
- Byt sökmotor i alla dina webbläsare.
Byt webbläsare
Vill du ha en snabb, resurssnål webbläsare anpassad för din Mac så väljer du Apples egen Safari. Du får betydligt bättre batteritid i en bärbar Mac och du slipper att en massa information om det du gör landar hos Google. Webbläsarna Brave och Firefox är två andra riktigt bra alternativ och känner du att du absolut inte kan ge upp en del av de funktioner som finns i Google Chroem så bygger Brave på samma kod, har samma funktioner men Brave snokar inte på dig.
Kasta ut Alexa och Google Home
Du kan inte förvänta dig att ha någon slags integritet, en privat sfär om du släpper in Googles smarta högtalare Google Home eller Amazons Alexa in i ditt hem. Ska du använda smarta funktioner hemma så välj Apples Home i kombination med Siri.
Välj bort datatrålarnas tjänster och produkter
Det finns ett skäl till att Google Home och Googles nätverkslösning för ditt lokala nät hemma är billigt i en jämförelse med konkurrerande produkter – de vill att du ska använda dem, ta med dem hem och koppla upp ditt hem mot deras tjänster, produkter och funktioner. Google har periodvis sålt en del av sina produkter subventionerade, med förlust, för att se till att vi köper dem, tar hem dem och kopplar upp oss. Det är därför det finns små smarta enheter för Google Home som kostar under 500 kronor – för att Google vet att det är en utmärkt insamlingspunkt för data.
Välj bort Google Documents, Gmail och andra lösningar, produkter och tjänster från Amazon, Facebook och Google om du ska minska din exponering.
Byt telefon
Sitter du idag med en mobiltelefon med Android under skalet, och du inte har gedigna tekniska kunskaper för att kunna byta ut Android, så är du en guldgruva för Google. Du använder Googles webbläsare, söktjänst och du kanske lagrar dina bilder hos sökjätten och använder en rad av de tjänster som följer med en Android-telefon. Därmed har Google en rad enskilda insamlingspunkter som sammantaget ger sökjätten stora mängder användbar information om dig.
- Byt telefon, surfplatta och dator
Nej, jag vet mycket väl att det kanske inte är realistiskt och att det inte fungera för många. Jag vet också att Apples prylar upplevs som dyra, även om det finns en rad olika iPhone-modeller att välja mellan, i olika prisklasser, men på datorsidan så finns inga direkt billiga Apple-datorer. Ett byte av dator, mobiltelefon och surfplatta är inte något som alla kan göra, av kostnadsskäl eller av andra orsaker. Det du gör kanske kräver en Windows-dator eller så har du fått en Android-telefon av jobbet. Trots det så om du vill minska exponeringen mot de här teknikjättarna, om du vill göra det svårare för dem att smala in information om dig så är de prylar du använder viktiga i sammanhanget.
Din TV
Din TV är nästa viktiga insamlingspunkt och en uppkopplad tv är en guldgruva. Våra tv-vanor avslöjar vad vi är intresserade av, vad vi tittar på, när och hur länge. Därmed inte sagt att du behöva bytta TV men den behöver kanske inte vara uppkopplad på nätet.
Vill du ändå ha tillgång till bra tjänster, funktioner och appar så rekommenderas AppleTV.
Håll koll
Slutligen – håll koll.
Vilka data samlar en tjänst in om dig?
Läs avtalen även om det tar tid och är krångligt. Ta reda på om information skickas vidare och till vem eller vilka. Med Apples Safari så kan du se vad en webbtjänst samlar in om dig.
Här på Magasin Macken finns det 2 trackers – Google och OneSignal. Google därför att det finns en översättningstjänst installerad och OneSignal är notiser. Det är långt under genomsnittet för en webbplats av Magasin Mackens typ och för en ligg med nyhetsinnehåll. Du kan också se en sammanställning för hur ,nya trackers som stoppats (i Safari) och vilka tjänster/webbplatser det handlar om.
I Mac App Store och i Mapp Store finns det sedan deklarationer från utvecklarna vad de samlar in och hur informationen används. Du kan enkelt slå av flera av spårningsfunktionerna som används ute på nätet genom att slå av tredjeplats cookies och genom att slå av funktioner i iOS, iPadOS och macOS. Funktioner som är avslagna som standard så egentligen behöver du bara kontrollera att det är så.
Teknikeremit
Du kan minska din exponering, minska mängden data som samlas in om dig – utan att behöva lämna nätet, flytta ut i skogen och leva som en ensam teknikeremit. Du kan betyda att du får offra bekvämlighet och tillgänglighet men det finns inga genvägar. Har du inga problem med att det samlas in information om dig så gör du naturligtvis som du vill (det gör du oavsett) och här finns inga rätt eller fel. Det är du som väljer och det är din information. Du väljer vad du vill göra åt det.
av Mikael Winterkvist | nov 10, 2024 | Bluesky, Mastodon, Nätfrihet, Threads, Twitter
Den minnesgode kanske kommer ihåg AltaVista, Webcrawler, Lycos eller Yahoo – sökfunktioner ute på nätet – före Google. Idag dominerar amerikanska Google, stort, men det är en position som hotas av AI.
Google har sin egen AI-lösning, Gemini, men trots enorma resurser så bedöms Gemini ligga en bit efter Open AI och andra lösningar. Det i sin tur innebär att på sikt så kan Googles dominans vara hotad därför att kommande generationer av sökfunktioner kommer att vara AI-styrda sökmotorer – och de ligger inte långt bort, eller rättare sagt – de är här men de finns i sina första generationer.
Sammanfatta
AI kan sammanfatta, summera och göra det snabbt vilket gör att en sökning på nätet kan bli långt mera effektiv än idag. AI kan också, ganska snabbt, över tid lära sig vad en användare söker efter, inom vilka områden och därmed också bli mera träffsäker. Kommande generationer sökmotororer kan också hantera längre, mer komplexa frågeställningar och vartefter vi sm användare lär oss att skriva bättre instruktioner, bättre texter om vad vi letar efter så kommer vi också att hitta mer och snabbare.
Det är samma träning som krävs för att skriva instruktioner för en bildfunktion som drivs med AI. Ska du får ut de bilder du vill så kan det krökas lite träning för att skriva rätt instruktioner.
ChatGPT
Idag rankas Open AIs ChatGPT ligga i framkant och gör du sökningar med ChatGPT så kommer du kanska snart att upptäcka att i vissa lägen, för viss information så får du bättre, mer korrekta svar. Google är också beroende av att samla in information för hela sin affärsverksamhet. Det är det Google gör, det är hela affärsidén – samla in enorma mängder data, analysera, packa om och söla tjänster kopplade till allt Google vet om oss. Vi är produkten.
Börjar vi som användare att använda andra söktjänster så kommer dataunderlaget för Googles verksamhet att minska. Lägg sedan till att Apple, med miljarder enheter som använder Google som standard, processar merparten av alla AI-data lokalt, alternativt i ett skyddat moln där varken Apple eller någon annan samlar in någon information för att skicka vidare så kan Googles datatrålande vara hotat – på sikt.
Nyansera
För att nyansera det hela något – detta är inget akut hot, inget som hotar sökjätten just i detta nu men på sikt så kan det innebära att dagens mera enhetliga bild där de flesta säker med Google – inte gör det längre. Vi kan vara på väg tillbaka med en rad olika sökmotorer – så som det sig ut innan Google tog över och slog ut i stort sett alla konkurrenter.
av Mikael Winterkvist | okt 25, 2024 | Bluesky, Mastodon, Nätfrihet, Threads
Har du uppgraderat Firefox nyligen så har du sannolikt aktiverat det som kallas “Privacy Preserving Attribution” (PPA), utan att du vet om det och utan att ha fått information om att funktionen slås på, som standard.
Mozilla hävdar att ”privacy preserving attribution” förbättrar användarnas integritet genom att tillåta att annonsresultat kan mätas utan att enskilda webbplatser samlar in personlig information. Spårningen gör nu direkt i Firefox, i webbläsaren. Mozilla hävdar vidare att detta är mindre invasivt än obegränsad spårning, vilket fortfarande är normen i USA, men det står i strid med GDPR, skriver European Digital Rights (EDRi).
“Mozilla has just bought into the narrative that the advertising industry has a right to track users by turning Firefox into an ad measurement tool. While Mozilla may have had good intentions, it is very unlikely that ’privacy preserving attribution’ will replace cookies and other tracking tools. It is just a new, additional means of tracking users.”
EDRi riktar också hård kritk mot Mozilla och Firefox för att ha aktiverat funktionen, utan att informera om det, utan att förklara vad funktionen gör och utan tillstånd från användaren. Funktionen nämns inte ens i Mozillas dataskyddspolicy.
Enda sättet för användare att stänga av det är att hitta opt-out-funktionen i en undermeny med webbläsarens inställningar.
av Mikael Winterkvist | okt 15, 2024 | Bluesky, Mastodon, Nätfrihet, Threads
Regeringen föreslår nu att att lagen om hemlig dataavläsning görs permanent. Regeringen föreslår även att polisen ska få större möjligheter att ta upp dna-prov och fingeravtryck.
Anledningen är ett den utredning, som regeringen tillsatt, kommit fram till att lagen måste vara kvar då det anses vara ”helt nödvändigt”.
– Det är mot den bakgrunden som regeringen har beslutat om en lagrådsremiss, där vi föreslår att lagstiftningen ska gälla fortsatt och utan tidsbegränsning, säger justitieminister Gunnar Strömmer (M) på en pressträff.
DNA-prov
Polisen ska även få utökade möjligheter att hämta in information – när det inte finns någon misstänkt. Polisen ska även få utökade möjligheter att ta upp och använda biometriska underlag, såsom dna-prov och fingeravtryck.
Lagändringarna om biometri föreslås börja gälla den 1 juli 2025 och lagändringarna om hemlig dataavläsning den 1 april 2025.
